Basándonos en las ofertas de generación energética que EOLICA AUDAX
(ADXVD04) ha registrado en el mercado de OMIE durante 2023,
a continuación se presenta un análisis de anomalías en la serie
temporal.
En este tutorial, aprenderás como desarrollar un modelo de detección de anomalías en series temporales con Python a partir de un caso práctico.
Data
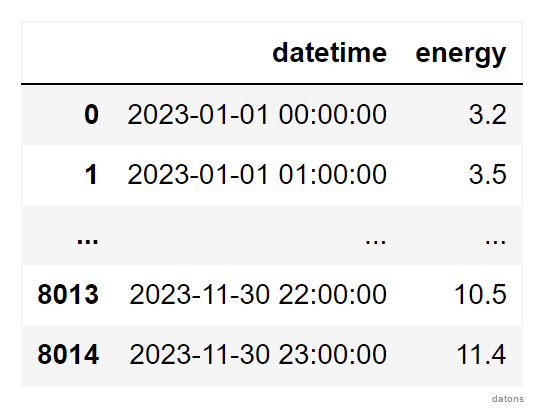
Cada fila representa la energía que la unidad ofertante
ADXVD04 ha registrado en el mercado de OMIE durante
2023.
import pandas as pd
df = pd.read_csv('data.csv')
Preguntas
- ¿Cómo se extraen las propiedades temporales para detectar anomalías?
- ¿Cómo utilizar el algoritmo Isolation Forest para identificar los datos anómalos?
- ¿Cómo se configura el algoritmo para detectar un porcentaje específico de datos como anómalos?
- ¿Qué técnicas se emplean para visualizar los datos anómalos en la serie temporal?
Metodología
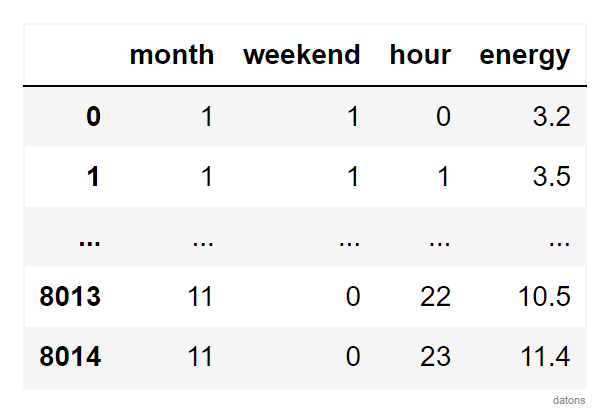
Columnas Temporales
Siguiendo los pasos de este tutorial, creamos las columnas temporales que puedan explicar el motivo de los datos anómalos.
df.datetime = pd.to_datetime(df.datetime)
df.set_index('datetime', inplace=True)
df = (df
.assign(
month = lambda x: x.index.month,
hour = lambda x: x.index.hour,
)
)
Modelo de Anomalías
Para detectar los datos anómalos, utilizamos el algoritmo
IsolationForest de la librería sklearn.
Establecemos el parámetro contamination a auto
para que el modelo detecte los datos anómalos de forma automática.
from sklearn.ensemble import IsolationForest
model = IsolationForest(contamination='auto', random_state=42)
model.fit(df_model)Porcentaje de Anomalías Automático
Utilizando la ecuación matemática que ha optimizado el algoritmo, calculamos los datos anómalos para visualizar el porcentaje de anomalías.
¿Conoces a alguien que podría interesarle este artículo? Compártelo con ellos.
df['anomaly'] = model.predict(df_model)
(df
.anomaly
.value_counts(normalize=True)
.rename(index={1: 'Normal', -1: 'Anomaly'})
.plot.pie()
)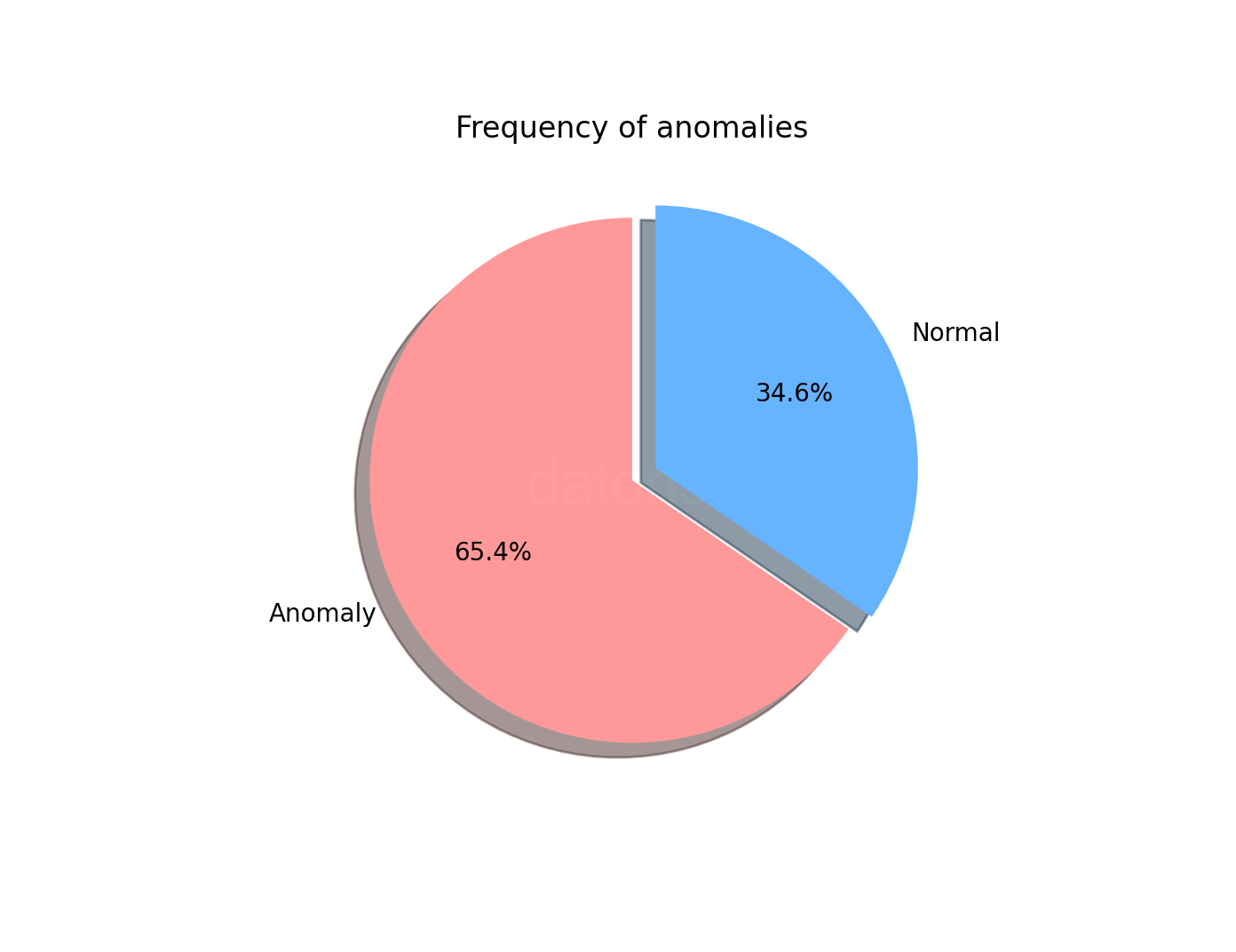
Un 65.4% de las ofertas de ADXVD04 son anómalas según la
configuración automática del modelo.
Especificar Porcentaje de Anomalías
No es lógico que la mayoría de los datos sean considerados anómalos.
Por tanto, ajustamos el parámetro contamination a
0.01 para que el modelo detecte el 1% de los datos como
anómalos.
model = IsolationForest(contamination=.01, random_state=42)
model.fit(df_model)
df['anomaly'] = model.predict(df_model)Visualizar Serie Temporal con Anomalías
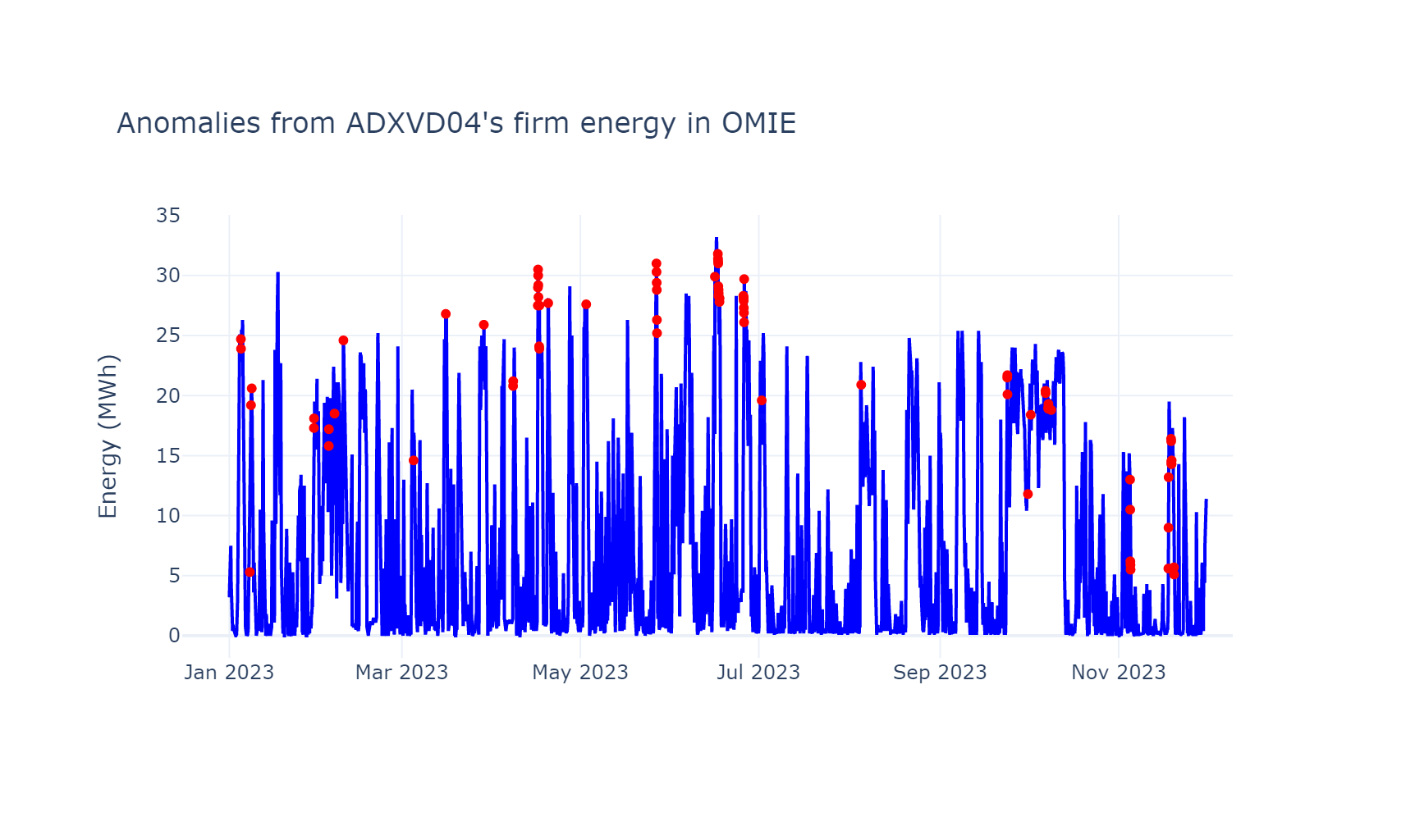
Finalmente, seleccionamos los datos anómalos:
s_anomaly = df.query('anomaly == -1').energyY los visualizamos con puntos sobre la serie temporal original
utilizando la sublibrería graph_objects de
plotly.
import plotly.graph_objects as go
go.Figure(
data=[
go.Scatter(x=s_anomaly.index, y=s_anomaly, mode='markers'),
go.Scatter(x=df.index, y=df.energy, mode='lines')
]
)Podemos observar que el modelo detecta observaciones anómalas, sobretodo, en los picos de la serie temporal.
¿Qué más podríamos hacer para analizar las anomalías? Te leo en los comentarios.
Conclusiones
- Extracción de Propiedades Temporales:
df.assignpara crear columnasmonthyhoura partir delDateTimeIndex. - Algoritmo
IsolationForest:sklearntiene el algoritmo registrado en su framework de Machine Learning. - Ajuste del Modelo para Porcentaje Específico de
Anomalías:
IsolationForest(contamination=0.01)ajusta la sensibilidad del modelo para identificar el 1% de los datos como anómalos. - Técnicas para Visualizar Datos Anómalos:
plotly.graph_objects.Figurenos permite combinar en una visualización los datos anómalos y la serie temporal original.
Me encantaría escuchar tus opiniones para mejorar nuestros futuros artículos.
¿Qué te pareció más interesante/valioso de este artículo?
¿Hay algún tema que te gustaría que cubriéramos en el futuro?
Tu feedback es crucial para generar contenido de alta calidad que se alinee con tus necesidades e intereses.
¡Gracias por tu atención y apoyo de antemano!
